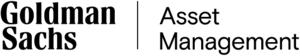Random Walk Part 4 – Can We Beat a Radically Random Stock Market?
Membership required
Membership is now required to use this feature. To learn more:
View Membership BenefitsThis is the final article of my four-part series into the fallacy of the random-walk paradigm. In Part 1 and Part 2, I showed that asset prices do not follow a tidy bell curve and instead are radically random. In Part 3, I demonstrated that many bad risk management practices are the direct results of equating volatility to risk. In this article, I offer a probability-based framework that captures the true nature of investment reward and risk.
The Efficient Market Hypothesis (EMH) argues that the market is hard to beat because very few people could make better forecasts than the collective market wisdom, which instantly discounts all available information. My new reward-risk framework reveals a little-known secret that market gains and losses have very different distribution profiles. We can beat the S&P 500 not by making better forecasts, but by exploiting the dual personality of Mr. Market.
The random walk theory has been the core of modern finance since Louis Bachelier wrote his 1900 PhD thesis. Economists define reward as the mean return (expected value) and risk as the standard deviation (volatility) of the returns. These mathematical terms may be convenient for academics in formulating their economic theories, but make no sense to the average investor. Reward has a positive overtone but mean could be negative. Risk has a negative undertone but standard deviation weighs gains and losses equally. Investors view reward and risk as two sides of the same coin – reward comes from gains and risk comes from losses. My reward-risk framework quantifies this subtle diametrical symmetry.
The random-walk definitions of investment reward and risk
Modern finance adopted the mean-variance paradigm to frame reward and risk. Appendix A presents the mathematical definitions. Figure 1 illustrates the reward and risk graphically with the annual returns of the S&P 500 from 1928 to 2016 (data sources: MetaStock and Yahoo Finance). The dark blue curve is the random walk probability density function (PDF). Reward (mean or expected value) is computed by integrating the total area under the PDF curve using equation A1 in Appendix A. Risk (the square root of variance), computed with equation A2, is one-half of the width of the light blue central region bounded by ± one standard deviation. The random walk PDF roughly matches the data (the jagged gray area) in the central region except near the peak. Beyond ± one standard deviations, data reside mostly above the PDF curve.
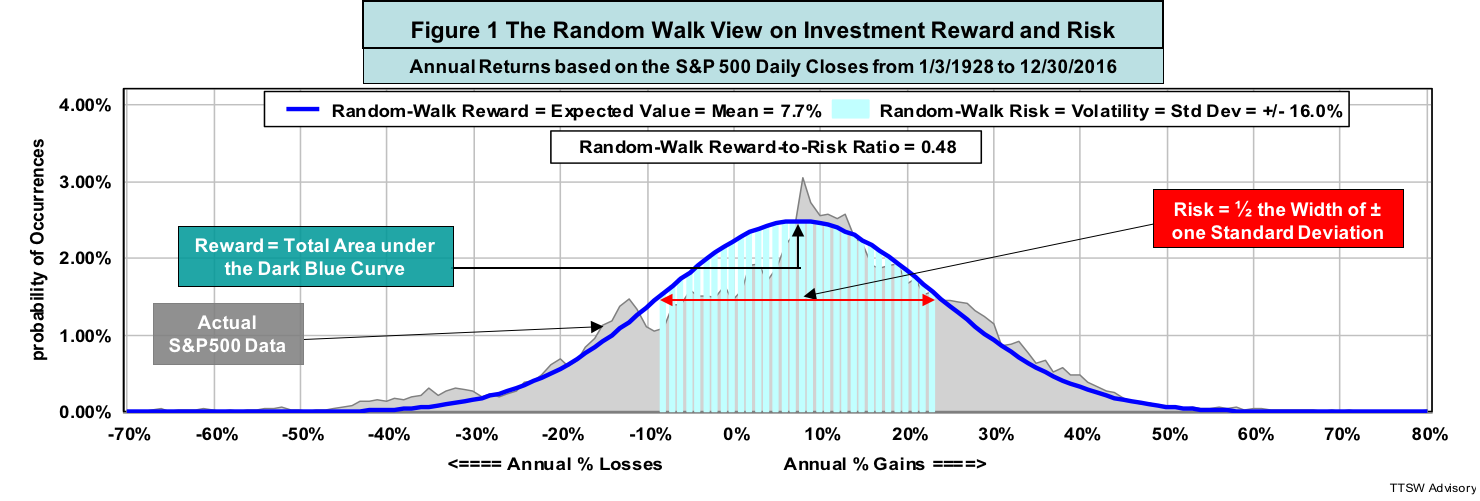
Figure 2 compares the random walk PDFs (blue curves) to the actual S&P 500 returns (gray areas) in a one-, five- and 10-year horizon. The peaks of the PDFs denote the means. The red arrows signify ± one standard deviations. Random walk's notions of mean and volatility bear no resemblance to actual returns and risks in the real world. The longer the return horizons are, the larger the gaps. This is why so many conventional risk management practices derived from the mean-variance paradigm broke down during financial crises. The academics' bell curve paradigm offers investors no protection against financial market risks.
My gain-loss framework for investment reward and risk
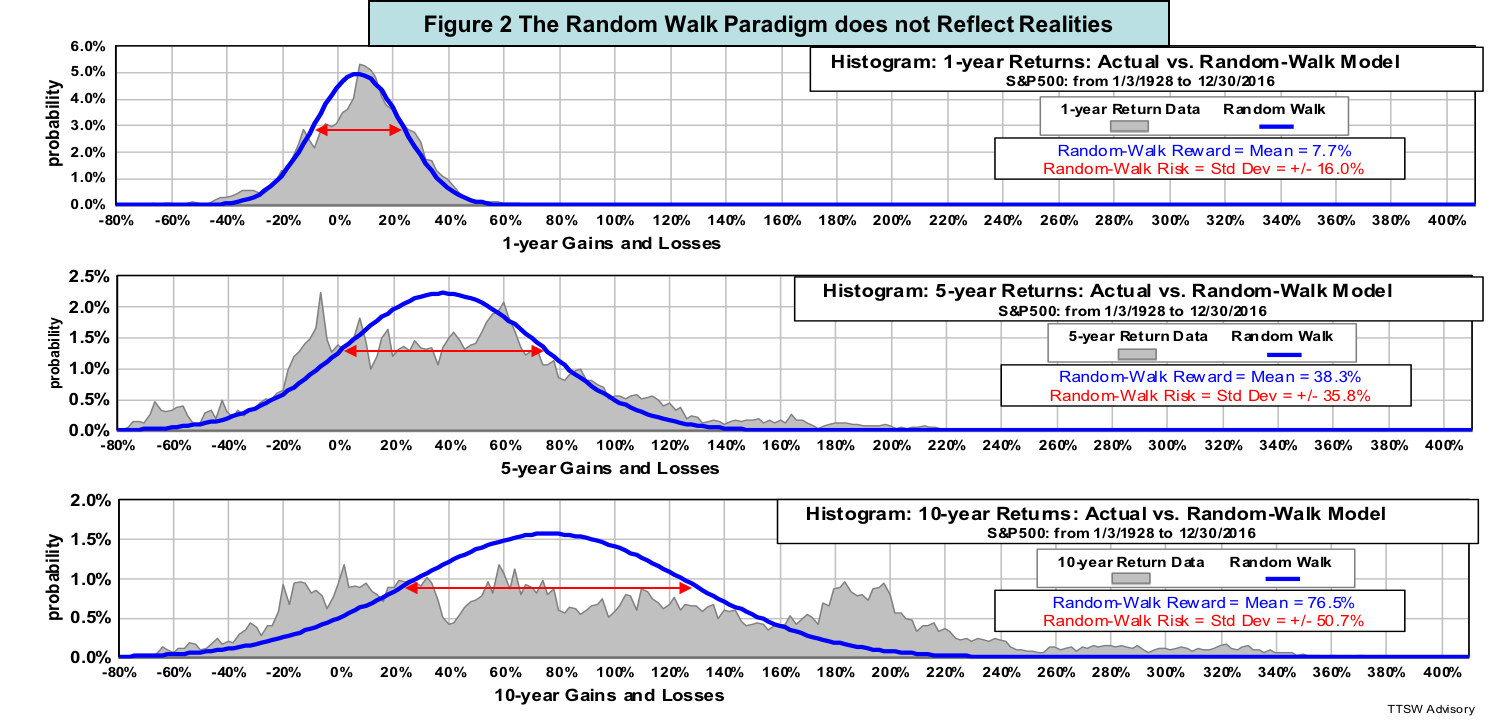
I offer a new probability-based framework for defining reward and risk. The formulas are presented in Appendix B. Figure 3 illustrates the concept. I define investment reward as the expected gain – the sum of all probability-weighted gains in a return histogram. It is computed by integrating numerically the total green area in Figure 3 using equation B1 in Appendix B. I define risk as the expected loss – the sum of all probability-weighted losses. It is computed by summing the total pink area in Figure 3 using equation B2.
The random-walk paradigm treats both positive and negative dispersions as risks. The expected gain-loss framework only considers losses (red bars) as risks but views the widely disperse green bars (gains) as gainful opportunities. The bell curve does not include all data, especially those at the extremes. The new model accounts for all outlier gains and all tailed risks weighted by their observed probabilities.
The old paradigm versus the new framework
Besides being unrealistic and impractical, the random-walk paradigm has one more subtle fault that is underreported. Mean and variance have different units of measure – mean is in percent but variance is in percent-squared. For unit compatibility, William Sharpe was compelled to use standard deviation – the square root of variance in his Sharpe Ratio. Even so, mean and standard deviation still do not have contextual uniformity. Mean signifies the most probable outcome and standard deviation measures the spread of those outcomes. Comparing reward (mean) to risk (volatility) is like comparing apples and oranges. For instance, Figure 1 shows that the mean-to-volatility ratio of the S&P 500 is 0.48 (dividing a mean of 7.7% by a volatility of 16%). Does this imply that the reward of investing in the S&P 500 is less than half the risk?
By contrast, "expected gain" and "expected loss" are two sides of the same coin – returns with opposite signs. Unlike the Sharpe Ratio that lacks clarity, the expected-gain-to-expected-loss ratio has absolute significance. For instance, Figure 3 shows that from 1928 to 2016, the S&P 500 index has an expected gain of 12.5% versus an expected loss of -4.3%. The expected gain of the S&P 500 is 2.9 times larger than the size of the expected loss.
Challenging the EMH's explanation on why the market is hard to beat
Why is the S&P 500 total-return such a formidable challenge for many active managers and market timers? The Efficient Market Hypothesis (EMH) offers a two-part explanation. First, market prices instantly (efficiently) reflect the collective appraisals of all market participants. Second, one can only beat the market by outsmarting the collective wisdom. On the surface, both points appear logical, but they are not, in fact, as logical as they appear.
The first point may explain why it is difficult for arbitrageurs to make a living because any price gap is instantly exploited. This argument, however, does not apply to the financial markets where prices are not single-valued functions of information. The same news can have multiple meanings and price implications depending on the receivers. Different interpretations of the same news draw buyers and sellers to the table. Price is an equilibrium point where the sellers believe their price is fair but high, while the buyers think is reasonable but low. The market is not a super forecaster, but an efficient auction-clearing house that facilitates buyers and sellers with different appraisals to transact.
The second EMH argument is self-inconsistent. It asserts that few can beat the market because outsmarting the collective forecast is hard to do. No random-walk followers including the EMH faithful should endorse the practice of forecasting because forecasting randomness is a contradiction in terms. Randomness, by definition, is unpredictable.
The real reason why the market is hard to beat
My gain-loss framework offers a painfully obvious explanation of why the market is hard to beat. Figure 4 parses the same data in Figure 2 in terms of gains and losses. It shows that the market offers investors abundant gainful opportunities (green bars), but that they are highly erratic. The probabilities inside the blue rectangle in the middle chart are nearly the same but the gains span from 0% to 80%. The bottom chart shows comparable probabilities for gains ranging from 0% to 200%. To time the market with virtually flat gain distributions is futile. That is why the buy-and-hold approach is unbeatable in the green zone.

The characteristics of market losses (pink bars) are very different. First, the pink zones are much narrower than the green areas. Second, while the green area grows with time (from 12.5% in one year, to 46.6% in five years and 101.7% in 10 years), the pink areas are insensitive to the holding period. In fact, as the holding period expands from five to ten years, the pink area shrinks from -5.2% to -2.9%.
It is a fool's errand to time the market in the green areas, where the probabilities are almost flat and the distributions grow with the holding period. It is prudent to stay in the market and gather those wildly erratic gains. In contrast, the pink areas are confined and insensitive to time. Hence, mitigating losses in the pink areas is much more manageable. My gain-loss framework not only explains why it is hard to beat the market, but also reveals a clue on how to do it logically.
Unlock a little-known market beating secret
How can we differentiate whether the current market is in the green or pink zone? I previously published five models that were designed to do just that. The five models are Holy Grail, Super Macro, TR-Osc, Primary-ID and Secondary-ID. They detect the green/pink market phases from five orthogonal perspectives – trend, the economy, valuations, major market cycles and minor price movements, respectively.
Figure 5 shows the annual return histograms of the five models against three investment benchmarks – the S&P 500 total-return, the 10-year US Treasury bond, and the 60/40 mix (60% equity and 40% bond rebalanced monthly) (data: Shiller). They were computed from the eight equity curves – the compound growths from January 1900 to September 2017.
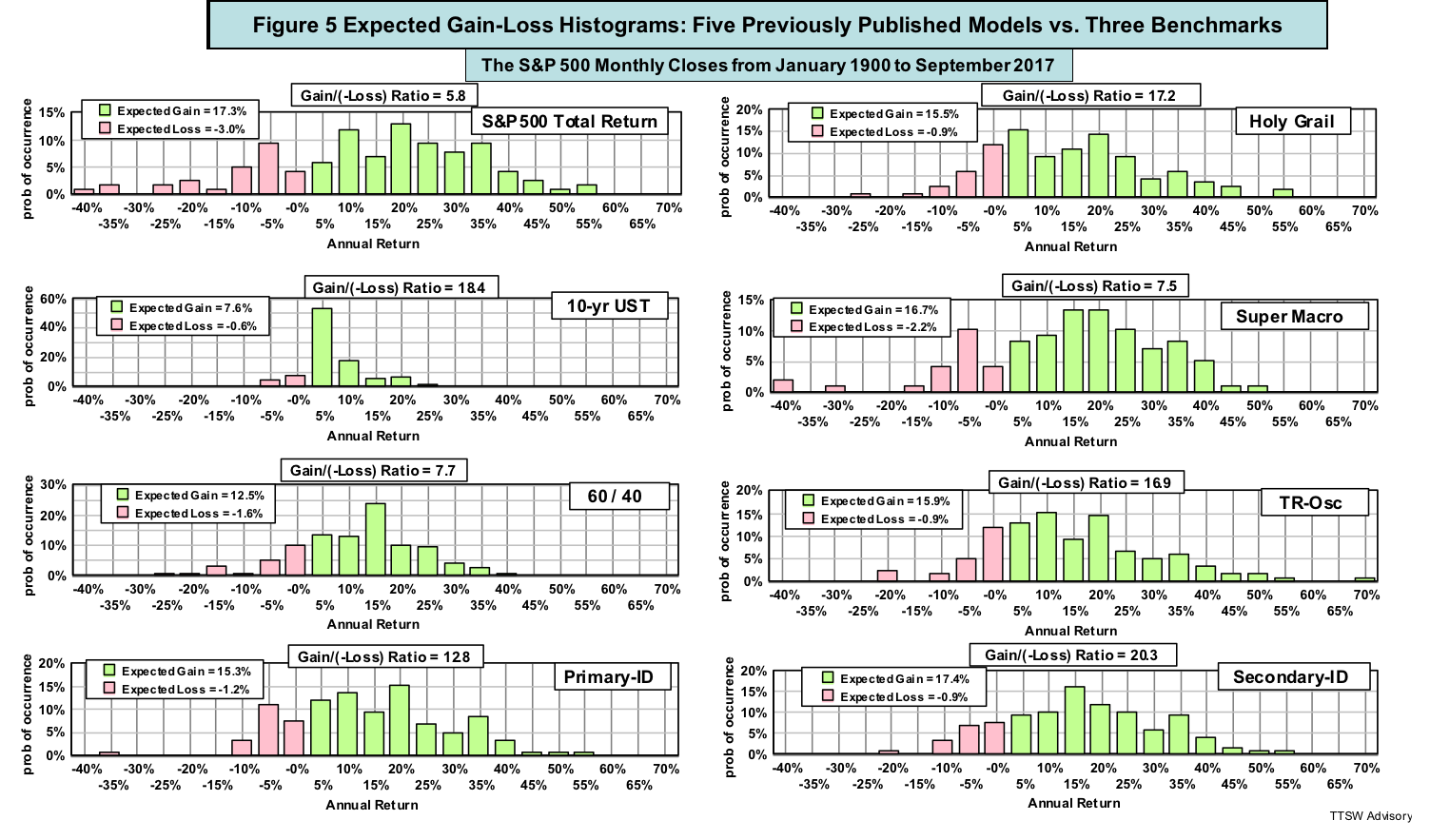
Figure 5 shows that my five models share two common features: their green bars are comparable to those of the S&P 500 but with narrower pink areas. In other words, their expected gains are as good as the S&P 500 but their expected losses are much lower. As a result, they offer much higher expected gain-to-loss ratios than that of the S&P 500. A model with a higher expected gain-to-loss ratio than the S&P 500 can surely beat the market return. I will quantify this point a bit later but first, I must challenge yet another modern finance doctrine.
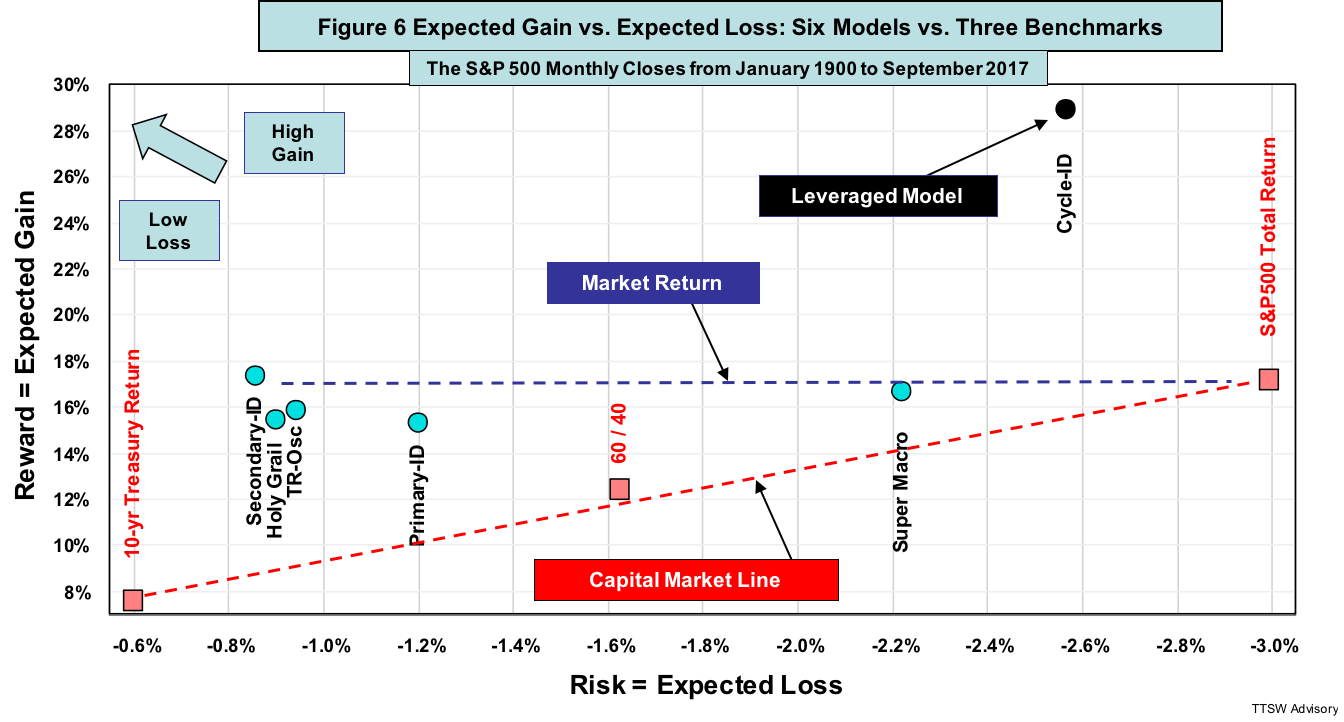
Challenging the Capital Asset Pricing Model
The Capital Asset Pricing Model (CAPM) asserts that first, no return of any asset mix between the S&P 500 and the Treasury bond or Treasury bill can exceed the Capital Market Line (CML); and second, one can only increase return by taking on more risk via leverage. Figure 6 is a plot of expected gains versus expected losses from the data in Figure 5. The dashed red line is the CML connecting the S&P 500 total-return to the 10-year US Treasury bond total-return (bond yields plus bond price changes caused by interest rate changes). Also shown are my five models (light blue dots) and the three benchmarks (red squares). I add a sixth model Cycle-ID (black dot) to show the effects of leverage. All six models are counterexamples to the CAPM. The five unlevered models reside far above the CML. The levered Cycle-ID beats the S&P 500 expected gain by 68% with only 85% of the risk. Hence, both CAPM claims are untrue.
CAGR and maximum drawdown comparisons
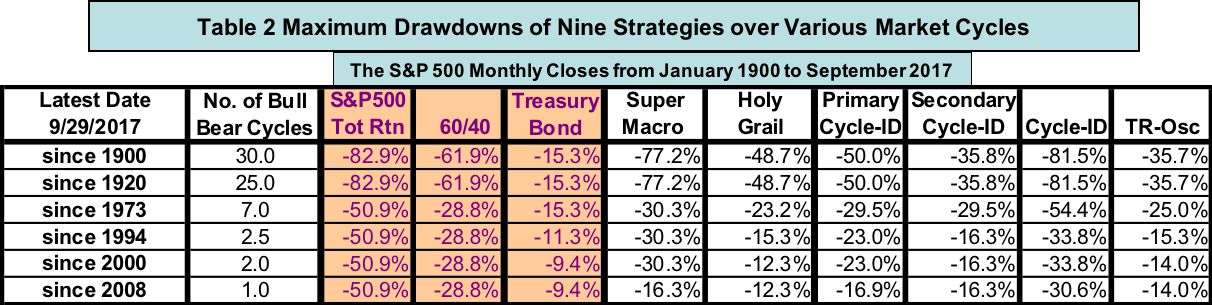
It is simple math that investors can beat the S&P 500 total-return if they can achieve close to the S&P 500 expected gains but cut their expected losses sizably relative to the S&P 500. Table 1 lists the compound annual growth rates (CAGRs) of all nine strategies in six sets of bull and bear full market cycles from January 1900 to September 2017. All six models have CAGRs higher than the S&P 500 total-return consistently in different bull and bear full cycles over a century.

My six models not only outperform the total compound returns of the S&P 500 in all cycle sets, they also offer lower risks than the S&P 500 measured by maximum drawdown. Table 2 compares maximum drawdowns of the nine strategies in different market cycles.
A dynamic active-passive investment approach
Which investment approach is better, passive or active? This ongoing debate misses the point. There is a time to be passive and a time to be active. Passive investors underperform active managers in bear markets and active investors are no match to buy-and-holders in bull markets.
Figure 4 reveals that Mr. Market has a dual personality. When he is content, he spreads his random gains over a wide green area. When he is mad, he directs his wrath at a narrow pink zone. Therefore it is feasible to logically beat Mr. Market at his own game – be a passive investor in the green areas to gather the wildly disperse gains but be an active risk manager in the pink areas to trim market losses.
Here is how investors can do that in practice. Do regular checkups on Mr. Market's health. If we detect a mood shift from good to bad, reduce market exposure (actively preserve capital in the pink zones). Otherwise, we stay in the market (passively cumulate wealth in the green areas).
Market health checkups are not market forecasts. Doctors do not forecast our medical conditions at annual exams. They conduct routine diagnoses and look for symptoms. If some tests come back positive, then the doctors actively treat those illnesses. Otherwise, patients would passively count their blessings until the next checkup.
Similarly, in regular market health checkups, we do not forecast market outlook but conduct diagnoses and look for warning signs. For instance, my five models were designed to monitor subtle shifts in trend (Holy Grail), the economy (Super Macro), valuation (TR-Osc), major market cycle (Primary-ID) and minor price movement (Secondary-ID). When a medical test comes back positive, we do not panic but seek second or third opinions. Likewise, investors should not assess market health based on a single indicator, but use the weight-of-evidence from multiple orthogonal models.
Using this dynamic active-passive approach and developing an integrated market monitoring system, investors can achieve the dual objective of capital preservation in bad times and wealth accumulation in good times.
Concluding Remarks
The key findings from all four random-walk series are summarized below:
1. Modern finance assumes that all asset prices follow a random walk. The academics define reward as the mean return at the peak of a bell curve. Data taken from a variety of asset classes (Part 1 and Part 2) with return horizons from one day to 10 years are far too erratic to fit the random walk statistics.
2. The histograms of a variety of asset classes not only reject the bell curve, they do not fit any well-known analytical probability theory. The types of randomness observed are akin to Frank Knight's "radical uncertainties", Donald Rumsfeld's "the unknown unknowns" or Nassim Nicholas Taleb's "Black Swans".
3. In a multimodal histogram with no central tendency, mean and variance are ill defined. The mean-variance paradigm is unfit to depict real-world prices.
4. Modern finance misreads risk as volatility (Part 3). Volatility reflects diversity in market views when the act of buying or selling does not affect the price. Volatility facilitates trades, lubricates liquidity and alleviates financial market risks. In contrast, a market with a single dominant view creates a buyer-seller imbalance. Risks come from uni-directional price movements that freeze liquidity and exacerbate bubbles or panics.
5. Investment risk comes in many forms – market risk, geopolitical events, inflation, currency, interest rate, recession, etc. Regardless the sources, all risks lead to the same outcome – an unacceptable loss in the form of income or capital, or both.
6. High uncertainties and radically random distributional gains are not risks, but represent abundant opportunities and widely scattered investment rewards.
7. I define investment reward as the cumulative probability-weighted gain; and investment risk as the cumulative probability-weighted loss. My new framework accurately captures all observed data and is applicable to probability distributions of any shape and form. More importantly, it has an intuitive appeal to investors.
8. A Random walk is a theory. A theory is supposed to describe and explain empirical observations. It provides analytical formulas that can predict the future. However, theories that hypothesize causation but disregard any aberration that does not fit their paradigms are theoretical landmines for all uninformed followers.
9. My gain-loss framework is not a theory, but a phenomenological model. It truthfully measures observations with statistical tools but offers no causation explanations or analytical formulas. As stated in Part 2, investors' adaptive behavioral dynamics render all analytical models in mathematical finance imprecise at best. An empirical model that objectively captures data with no theoretical bias is more practical for investors.
10. My new framework reveals that Mr. Market has a dual personality. He keeps his losses in time insensitive and confined zones but lets his gains run wild and loose. We can exploit this asymmetry to beat Mr. Market at his own game.
11. The active-passive investment approach capitalizes on this gain-loss asymmetry and tilts the betting odds in our favor. We actively mitigate losses in the pink zones via regular market health checkups. Otherwise, we stay as passive investors and pick up the radically random profits Mr. Market leaves behind.
12. How can we detect Mr. Market's mood changes? My six rules-based market monitors demonstrate that early warning detection is possible.
13. Warren Buffett consistently beats the market. He could be a practitioner of the dynamic active-passive approach because his favorite holding period is "forever" (a passive investor) subject to his first and second rules of "don't lose money" (an active manager).
Theodore Wong graduated from MIT with a BSEE and MSEE degree and earned an MBA degree from Temple University. He served as general manager in several Fortune-500 companies that produced infrared sensors for satellite and military applications. After selling the hi-tech company that he started with a private equity firm, he launched TTSW Advisory, a consulting firm offering clients investment research services. For almost four decades, Ted has developed a true passion for studying the financial markets. He applies engineering design principles and statistical tools to achieve absolute investment returns by actively managing risk in both up and down markets. He can be reached at mailto:[email protected].
Appendix A: The Mean-Variance Paradigm
Modern finance defines reward as the mean return (also known as the expected value). Mean return is the cumulative probability weighted return defined as follows:
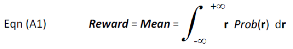
where r is return (a continuous random variable) and Prob(r) is the Gaussian probability density function (PDF) of r. The integration limits are - infinitive to + infinitive. The cumulative sum of Prob(r) is normalized to 100%.
Modern finance defines risk as volatility (also known as standard deviation). It is the cumulative probability weighted root-mean-squared (RMS) of the deviation of each r from Mean. The mathematical formula for risk is:
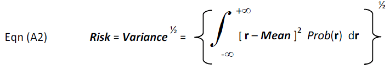
where Mean is given by Eqn (A1). The integration limits are - infinitive to + infinitive.
The reward-to-risk ratio is therefore the mean divided by the standard deviation. Replacing r in Eqn(A1) and Eqn(A2) by the quantity r minus the risk-free interest rate (this quantity is also known as the equity risk premium), the reward-to-risk ratio becomes the Sharpe Ratio.
Appendix B: The Gain-Loss Framework
Investors view reward and risk from a gain-loss perspective. The best way to capture this intuitive view is with a pair of complementary formulas called "Expected Gain" and "Expected Loss". Investment reward is the expected gain, which is the sum of all probability weighted positive returns. The formula is:
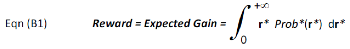
where r* is return (a discrete random variable) and Prob*(r*) is the observed probability of return r*. The cumulative sum of Prob*(r*) is normalized to 100%. The limits of integration are from zero to + infinitive, so only positive returns (gains) are summed. In Eqn (A1), r and Prob(r) are Gaussian function variables. In Eqn (B1), r* and Prob*(r*) are measured data.
Correspondingly, investment risk is defined as the expected loss, which is the sum of all cumulative probability weighted negative returns. The formula for expected loss is:
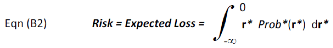
The integration limits are - infinitive and zero, namely, only negative returns (losses) are summed.
The reward-to-risk ratio is the expected gain divided by the expected loss, both of which are in percent.
Membership required
Membership is now required to use this feature. To learn more:
View Membership BenefitsSponsored Content
Upcoming Virtual Events View All