Advisor Perspectives welcomes guest contributions. The views presented here do not necessarily represent those of Advisor Perspectives.
The proverbial wisdom is that there are two types of stock market cycles – secular and cyclical. I argued previously that secular cycles not only lacked statistical basis to be credible, but their durations of 12 to 14 years are also impractical for most investors. We live in an internet age with a time scale measured in nanoseconds. Wealth managers often turn over their portfolios after only a few years. Simply put, secular cycles can last longer than financial advisors can retain their clients.
The second type of cycle is called a “cyclical market” and is believed to comprise both primary and secondary waves. Economic cycles are thought to drive primary waves. According to the National Bureau of Economic Research (NBER), the average economic cycle length is 4.7 years, which would be more suitable for the typical holding periods of most investors.
To succeed in accumulating wealth in bull markets and preserving capital in bear markets, we must first define and detect primary and secondary markets. In this article, I present a modeling approach to spot primary cycles. Modeling secondary market cycles will be the topic of Part 2.
Common flaws in modeling financial markets
Before presenting my model on primary markets, I must digress to discuss two common mistakes in modeling financial markets. For example, when modeling secular market cycles and market valuations, analysts use indicators such as the Crestmont P/E, the Alexander P/R and the Shiller CAPE (cyclically adjusted price-earnings ratio). By themselves, these indicators are fundamentally sound. It's the modeling approach using these indicators that is flawed.
Models on valuations and secular cycles cited above share two assumptions. First, they assume that the amplitude (scalar) of the indicators can be relied on to indicate market valuations and secular outlook. Extremely high readings are interpreted as overvaluations or cycle crests, and extremely low readings, undervaluation or cycle troughs. Second, it's assumed that mean reversion will always drive the extreme readings in the models back into line.
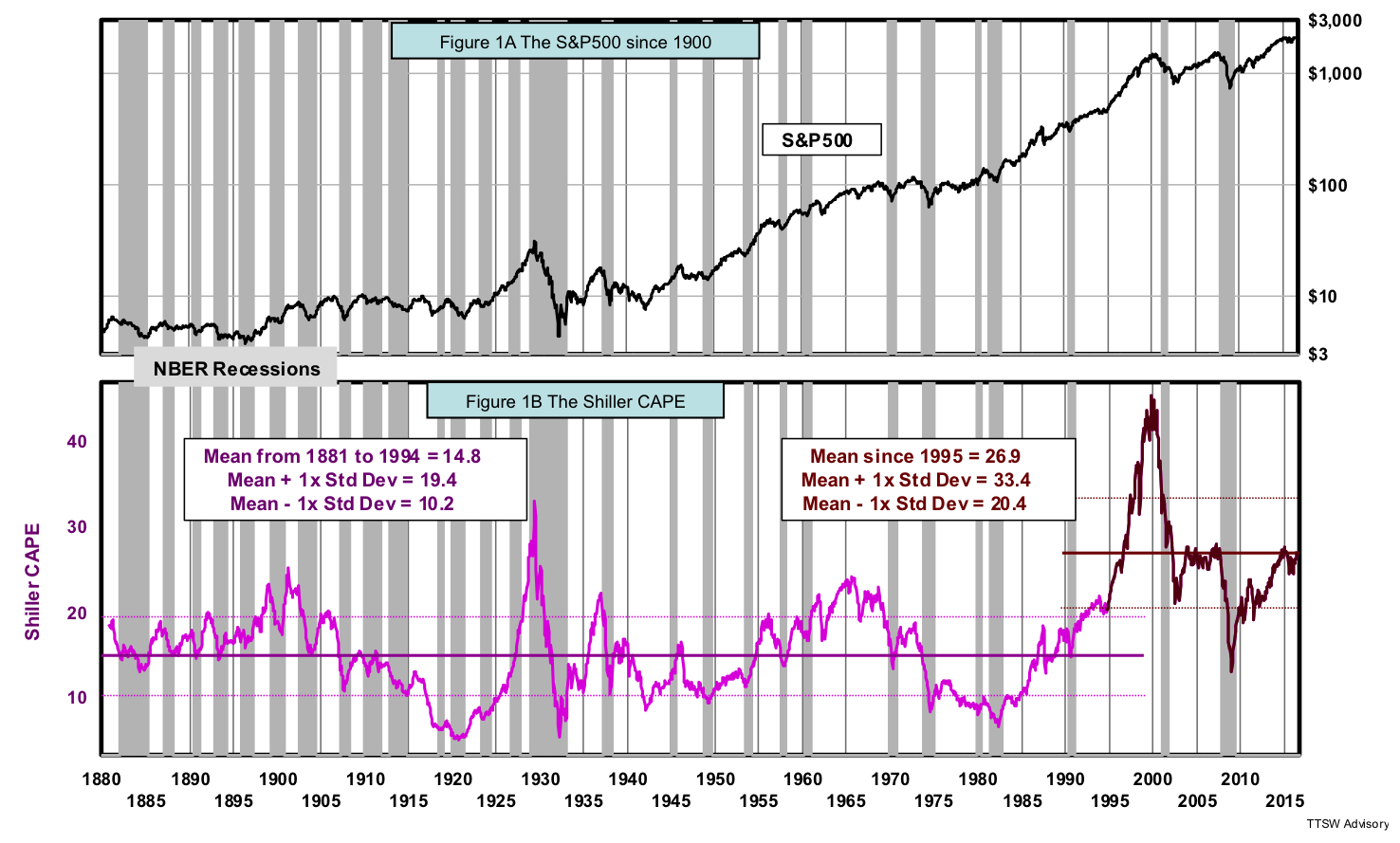
Figure 1A shows the S&P 500 from 1881 to mid-2016 in logarithmic scale. Figure 1B is the Shiller CAPE overlay. The solid purple horizontal line is the mean from 1881 to 1994 and has a value of 14.8. The upper and lower dashed purple lines represent one standard deviation above and below the mean of 14.8, respectively. The solid brown line to the right is the mean from 1995 to mid-2016 and has a value of 26.9. The upper and lower dashed brown lines are one standard deviation above and below the post-1995 mean of 26.9, respectively. One standard deviation above the pre-1995 mean is 19.4 and one standard deviation below the post-1995 mean is 20.4. The data regimes in the two adjoining timeframes do not overlap. The statistically distinct nature of the two regimes invalidates the claim by many secular cycle advocates and CAPE-based valuations practitioners that the elevated CAPE readings after 1995 are just transitory statistical outliers and will fall back down in due course.

Let's examine the investment impacts from these two assumptions. The first assumption is that extreme amplitudes can be used to track cycle turning points. Figure 1B shows that both high and low extremes are arbitrary and relative. As such, they cannot be used as absolute valuation markers. For example, after 1995, the entire amplitude range has shifted upward. Secular cyclists and value investors would have sold stocks in 1995 when the CAPE first pierced above 22, exceeding major secular bull market crests in 1901, 1937 and 1964. They would have missed the 180% gain in the S&P 500 from 1995 to its peak in 2000. More recently, the CAPE dipped down to 13 at the bottom of the sub-prime crash. Secular cycle advocates and value investors would consider a CAPE of 13 not cheap enough relative to previous secular troughs in 1920, 1933, 1942, 1949, 1975 and 1982. They would have asked clients to switch from stocks to cash only to miss out the 200% gain in the S&P 500 since 2010. These are examples of huge upside misses caused by the first flawed assumption used in these scalar-based models.
The second assumption is that mean reversion always brings the out-of-bound extremes back into line. This assumption falters on three counts. First, mean reversion is not mean regression. The former is a hypothesis and the latter, a law in certain statistics like Gaussian distributions (the bell curve). Second, mean regression is guaranteed only for distributions that resemble a bell curve. If the distributions follow the power-law or the Erlang statistics, even mean regression is not guaranteed. Finally, neither mean regression nor mean reversion is a certainty if the overshoots are not by chance, but are the results of causation. Elevated CAPE will last as long as the causes (Philosophical Economics, Jeremy Siegel and James Montier) remain in place. The second assumption creates a false sense of security that could be very harmful to your portfolios.
The confusion caused by both of these false assumptions is illustrated in Figure 1B. For the 26.9 mean, reversion has already taken place in 2002 and 2009. But for the 14.8 mean, reversion has a long way to go. All scalar models that rely on arbitrary amplitudes for calibration and assume a certainty of mean reversion are doomed to fail.
A vector-based modeling approach
The issues cited above are the direct pitfalls of using scalar-based indicators. One can think of scalar as an AM (amplitude modulation) radio in a car. The signals can be easily distorted when the car goes under an overpass. Vector, on the other hand is analogous to FM (frequency modulation) signals, which are encoded not in amplitude but in frequency. Solid objects can attenuate amplitude-coded signals but cannot corrupt frequency-coded ones. Likewise, vector-based indicators are immune to amplitude distortions caused by external interferences such as Fed policies, demographics, or accounting rule changes that might cause the overshoot in the scalar CAPE. Models using vector-based indicators are inherently more reliable.
Instead of creating a new vector-based indicator from scratch, one can transform any indicator from a scalar to a vector with the help of a filter. Two common signal-processing filters used by electronic engineers to condition signals are low-pass filters and high-pass filters. Low-pass filters improve lower frequency signals by blocking unwanted higher frequency chatter. An example of a low-pass filter is the moving average, which transforms jittery data series into smoother ones. High-pass filters improve higher frequency signals by detrending irrelevant low frequency noise commonly present in the physical world. The rate-of-change (ROC) operator is a simple high-pass filter. ROC is defined as the ratio of the change in a variable over a specific time interval. Common time intervals used in financial markets are year-over-year (YoY) or month-over-month (MoM). By differentiating (taking the rate-of-change of) a time series, one transforms it from scalar to vector. A scalar only shows amplitude, but a vector contains both amplitude and direction contents. Let me illustrate how such a transformation works.
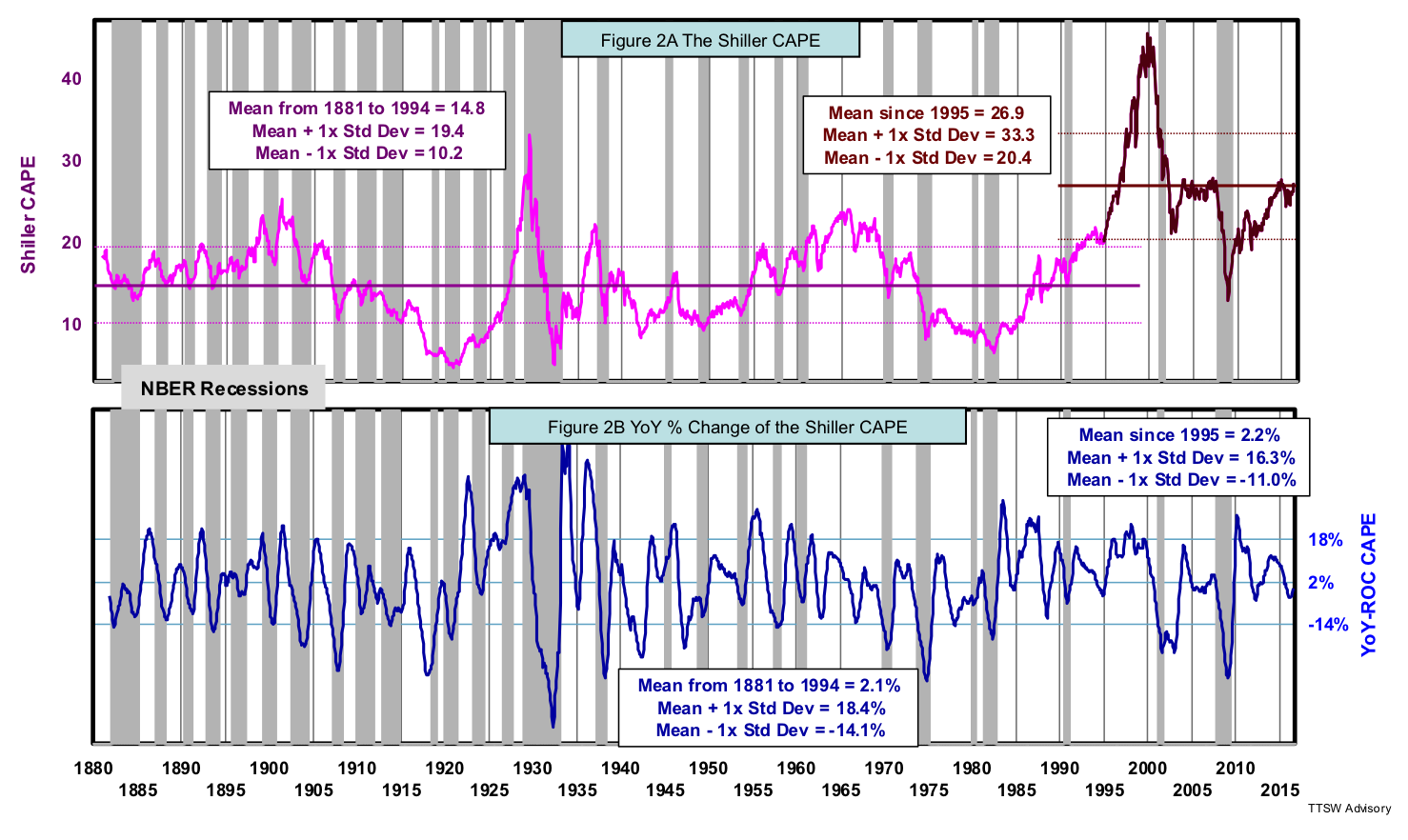
Figures 2A is identical to Figure 1B, the scalar version of the Shiller CAPE. Figure 2B is a vector transformation, the YoY-ROC of the scalar Shiller CAPE time series. There are clear differences between Figure 2A and Figure 2B. First, the post-1995 overshoot aberration in Figure 2A is no longer present in Figure 2B. Second, the time series in Figure 2B has a single mean, i.e. the mean from 1881 to 1994 and the mean from 1995 to present are virtually the same. Third, Figure 2B shows that the plus and minus one standard deviations from the two time periods completely overlap. This proves statistically that the vector-based indicator is range-bound across its entire 135-year history. Finally, the cycles in Figure 2B are much shorter than that in Figure 2A. Shorter cycles are more conducive to mean reversion.
It's clear that the YoY-ROC filter mitigates many calibration issues associated with the scalar-based CAPE. The vector-based CAPE is range-bound, has a single and stable mean and has shorter cycle lengths. These are key precursors for mean reversion. In addition, there are theoretical reasons from behavioral economics that vectors are preferred to scalars in gauging investors' sentiment. I will discuss the theoretical support a bit later.
The vector-based CAPE periods versus economic cycles
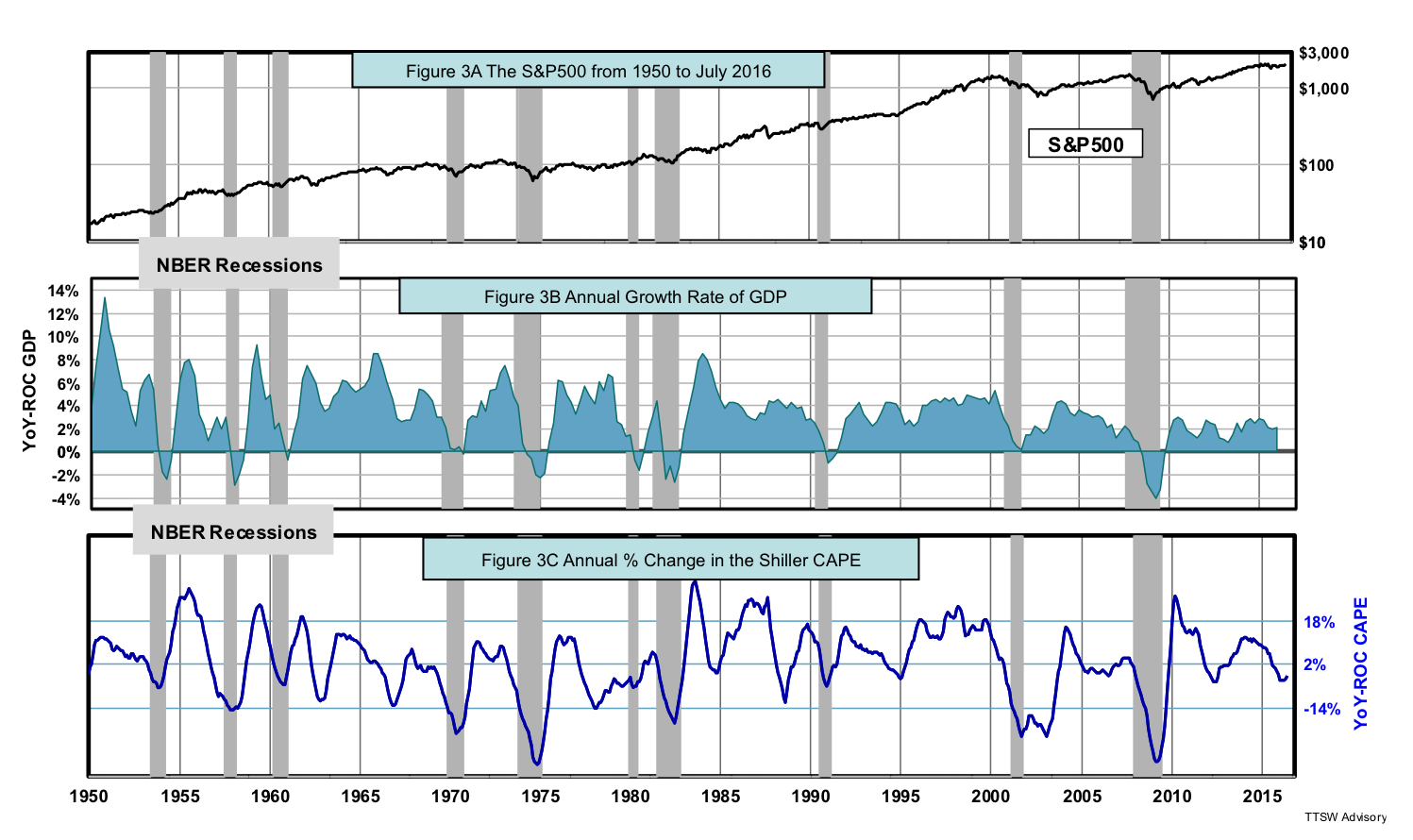
Primary market cycles are believed to be driven by economic cycles. Therefore, to detect cyclical markets, the indicator should track economic cycles. Figure 3A shows the S&P500 from 1950 to mid-2016. The YoY-ROC GDP (Gross Domestic Product) is shown in Figure 3B and the YoY-ROC CAPE in Figure 3C. The Bureau of Economic Analysis (BEA) published U.S. GDP quarterly data only after 1947.
The waveform of the YoY-ROC GDP is noticeably similar to that of the YoY-ROC CAPE. In fact, the YoY-ROC CAPE has a tendency to roll over before the YoY-ROC GDP dips into recessions, often by as much as one to two quarters. The YoY-ROC GDP and the YoY-ROC CAPE are plotted as if the two curves were updated at the same time. In reality, the YoY-ROC CAPE is nearly real-time (the S&P 500 and earnings are at month-ends and the Consumer Price Index has a 15-day lag). GDP data, on the other hand, is not available until a quarter has passed and is revised three times. The YoY-ROC CAPE indicator is updated ahead of the final GDP data by as much as three months. Hence, the YoY-ROC CAPE is a true leading economic indicator.
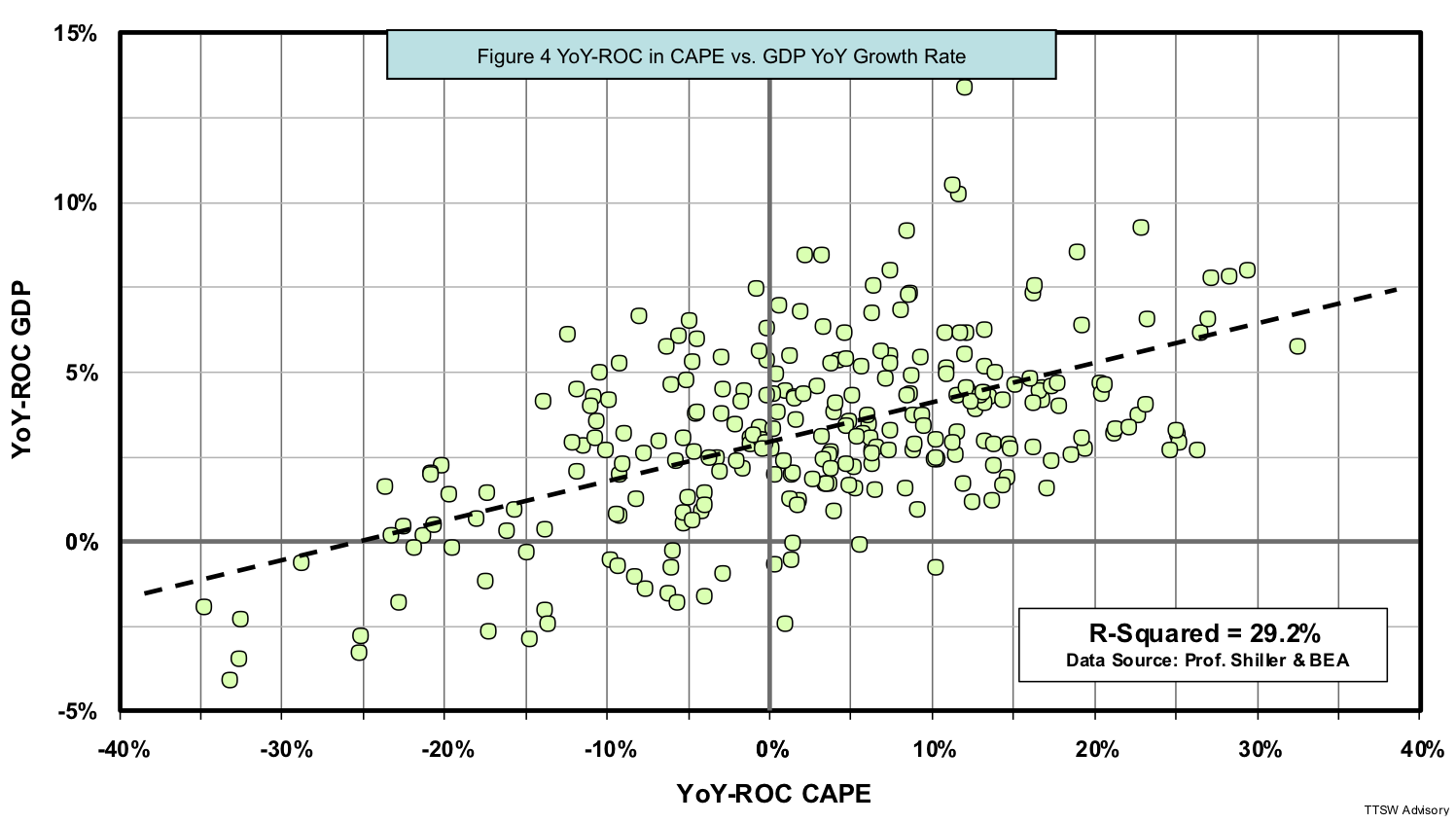
Although the waveforms in Figures 3B and 3C look alike, they are not identical. How closely did the YoY-ROC CAPE track the YoY-ROC GDP in the past 66 years? The answer can be found with the help of regression analysis. Figure 4 shows an R-Squared of 29.2%, the interconnection between GDP growth rate and the YoY-ROC CAPE. A single indicator that can explain close to one-third of the movements of the annual growth rate of GDP is truly amazing considering the simplicity of the YoY-ROC CAPE and the complexity of GDP and its components.
Primary-ID – a model for primary market cycles
Finding an indicator that tracks economic cycles is only a first step. To turn that indicator into an investment model, we have to come up with a set of buy and sell rules based on that indicator. Primary-ID is a model I designed years ago to monitor major price movements in the stock market. In the next article, I will present Secondary-ID, a complementary model that tracks minor stock market movements. I now illustrate my modeling approach with Primary-ID.
A robust model must meet five criteria: simplicity, sound rationale, rule-based clarity, sufficient sample size, and relevant data. Primary-ID meets all five criteria. First, Primary-ID is elegantly simple – only one adjustable parameter for "in-sample training." Second, the vector-based CAPE is fundamentally sound. Third, buy and sell rules are clearly defined. Forth, the Shiller CAPE is statistically relevant because it covers over two dozen samples of business cycles. Fifth, the Shiller database is quite sufficient because it provides over a century of monthly data.
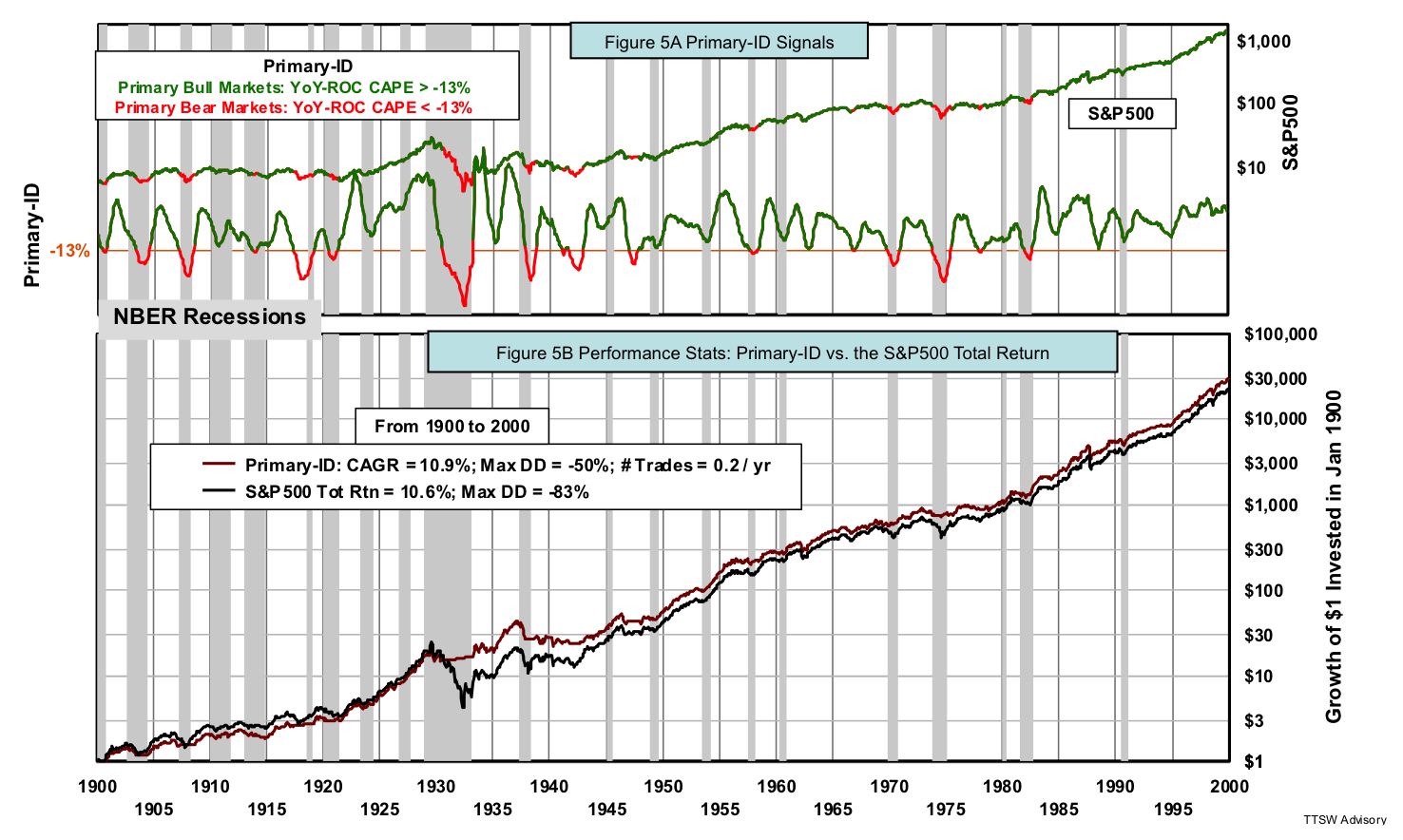
Figure 5A shows both the S&P 500 and the YoY-ROC CAPE from 1900 to 1999. This is the training period to be discussed next. The curves are in green when the model is bullish and in red when bearish. Bullish signals are generated when the YoY-ROC CAPE crosses above the horizontal orange signal line at -13%. Bearish signals are issued when the YoY-ROC CAPE crosses below the same signal line. The signal line is the single adjustable parameter in the in-sample training.
Figure 5B compares the cumulative return of Primary-ID to the total return of the S&P 500, a benchmark for comparison. A $1 invested in Primary-ID in January 1900 hypothetically reached $30,596 at the end of 1999, a compound annual growth rate (CAGR) of 10.9%. The S&P 500 over the same period earned $23,345, a CAGR of 10.3%. The 60 bps CAGR gap may seem small, but it doubles the cumulative wealth after 100 years. The other significant benefit of Primary-ID is that its maximum drawdown is less than two third of that of the S&P 500. It trades on average once every five years, very close to the average business cycle of 4.7 years published by NBER.
The in-sample training process
Figures 5A and 5B show a period from 1900 to 1999, which is the back-test period used to find the optimum signal line for Primary-ID. The buy and sell rules are as follows: When the YoY-ROC CAPE crosses above the signal line, buy the S&P 500 (e.g. SPY) at next month's close. When the YoY-ROC CAPE crosses below the signal line, sell the S&P 500 at next month's close and park the proceeds in US Treasury bond. The return while holding the S&P 500 is the total return with dividends reinvested. The return while holding bond is the sum of both bond yields and bond price percentage changes caused by interest rate changes.
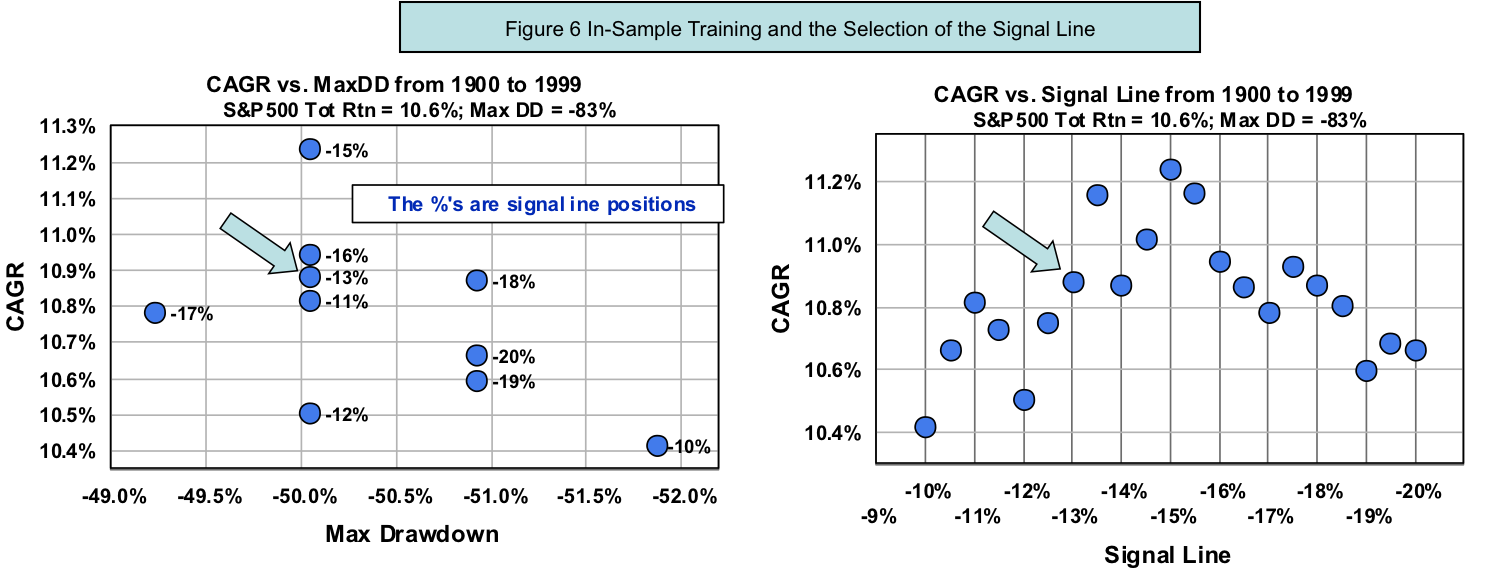
Figure 6 shows the back test results in two tradeoff spaces. The plot on the left is a map of CAGR versus maximum drawdown for various signal lines. The one on the right is CAGR as a function of the position of the signal line. For comparison, the S&P 500 has a total return of 10.6% and a maximum drawdown of -83% in the same period. Most of the blue dots in Figure 6 beat the total return and all have maximum drawdowns much less than that of the S&P 500.
Figures 6A and 6B only show a range of signal lines that offers relatively high CAGR. What is not shown is that all signal lines above -10% underperform the S&P 500. The two blue dots marked by blue arrows in both charts are not the highest returns nor the lowest drawdowns. They are located in the middle range of the CAGR sweet spot. I judiciously select a signal line at -13% that does not have the maximum CAGR. An off-peak parameter gives the model a better chance to outperform the optimized performance in the backtest. Picking the optimized adjustable parameter would create an unrealistic bias for the out-of-sample test results. Furthermore, an over-optimized model even if it passes the out-of-sample test is prone to underperform in real time. A parameter that is peaked during back-tests will likely lead to inferior out-of-sample results as well as actual forecasts.
Why do all signal lines above -10% give lower CAGR's than those within -10% and -19%? There is a theoretical reason for such an asymmetry to be discussed a bit later.
The out-of-sample validation
The out-of-sample test is a guard against the potential risk of over-fitting during in-sample optimization. It's like a dry-run before applying the model live with real money. Passing the out-of-sample test, however, does not necessarily guarantee a robust model but failing the out-of-sample test is certainly ground for model rejection.
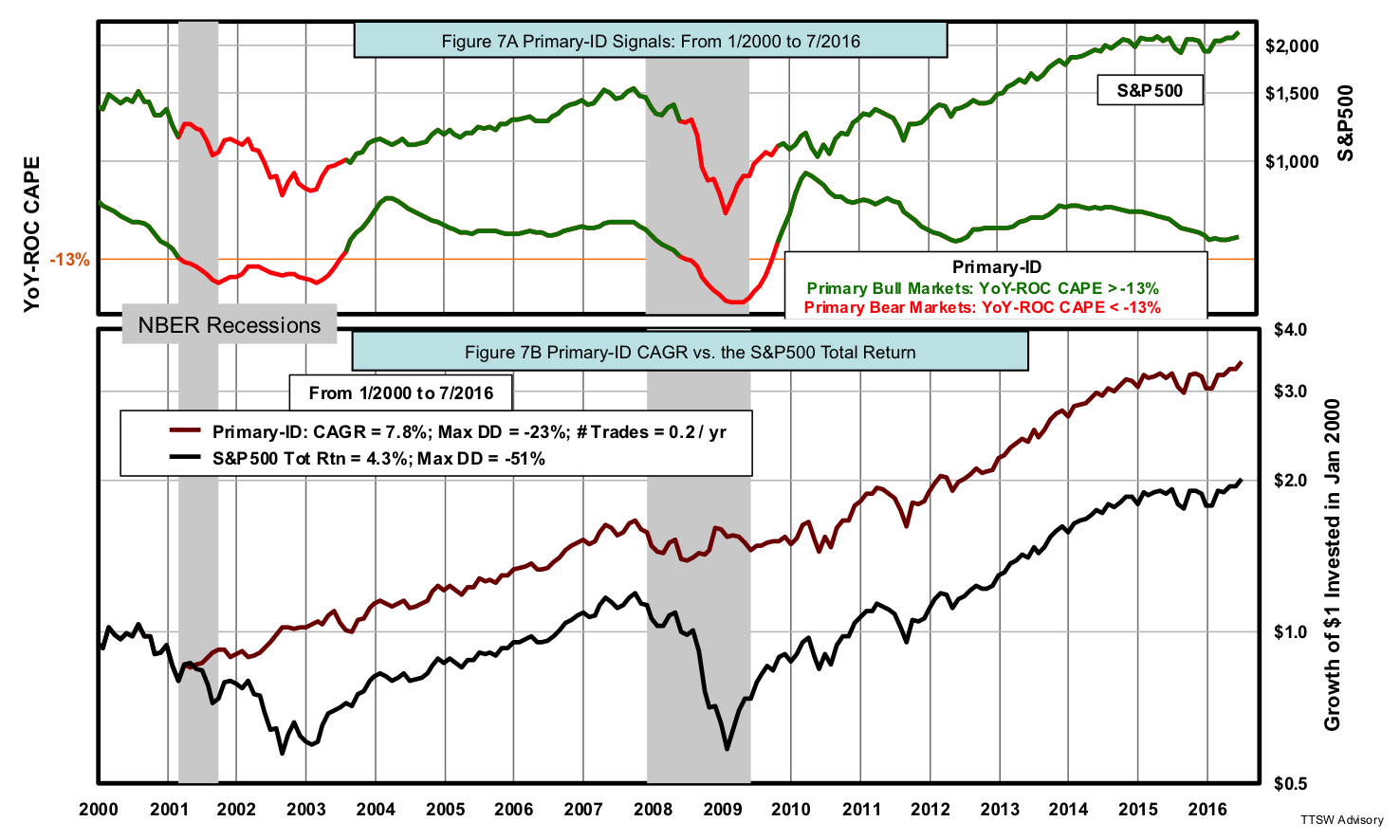
Here’s how out-of-sample testing works. The signal line selected in the training exercise is applied to a new set of data from January 2000 to July 2016 with the same buy and sell rules. Figure 7A shows both the S&P 500 and the YoY-ROC CAPE.
Figure 7B compares the cumulative return of Primary-ID to the total return of the S&P 500. A $1 invested in Primary-ID in January 2000 would hypothetically make $3.50 in mid-2016, a CAGR of 7.8%. Investing $1 in the S&P 500 over the same period would have earned $2.02, a CAGR of 4.3%. An added perk Primary-ID offers is the maximum drawdown of -23%, half of that of the S&P 500’s -51%. It trades on average once every five years, similar to that in the in-sample test, and therefore profits are taxed at long-term capital gains rates.
Primary-ID sidestepped two infamous bear markets: the dot-com crash and the sub-prime meltdown. It also fully invested in equities during the two mega bull markets in the last 16 years. The value of the YoY-ROC CAPE as a leading economic indicator and the efficacy of Primary-ID as a cyclical market model are validated.
Theoretical support for Primary-ID
The theoretical support for Primary-ID can be found in prospect theory proposed by Daniel Kahneman and Amos Tversky in 1979. Prospect theory offers three original axioms that lend support to Primary-ID. The first axiom shows that there is a two-to-one asymmetry between the pain of losses versus the joy of gains – losses hurt twice as much as gains bring joy. Recall from Figure 2B that the sweet spot for CAGR comes from signal lines located between -10% and -19%, more than one standard deviation below the mean near 0%. Why is the sweet spot located that far off center? The reason could be the result of the asymmetry in investors' attitude toward reward versus risk. Prospect theory explains an old Wall Street adage – let profits, run but cut losses short. Primary-ID adds a new meaning to this old motto – buy swiftly, but sell late. In other words, buy quickly once YoY-ROC CAPE crosses above -13% but don't sell until YoY-ROC CAPE crosses below -13%.
The second prospect theory axiom deals with scalar and vector. The authors wrote, "Our perceptual apparatus is attuned to the evaluation of changes or differences rather than to the evaluation of absolute magnitudes." In other words, it's not the level of wealth that matters; it's the change in the level of wealth that affects investors' behavior. This explains why the vector-based CAPE works better than the original scalar-based CAPE. The former captures human behaviors better than the latter.
The third prospect theory axiom proposed by Kahneman and Tversky is that "the value function is generally concave for gains and commonly convex for losses." Richard Thaler explains this statement in layman's terms in his 2015 book entitled "Misbehaving." The value function represents investors' attitudes toward reward and risk. The terms concave and convex refer to the curve shown in Figure 3 in the 1979 paper. A concave (or convex) value function simply means that investors' sensitivity to joy (or pain) diminishes as the level of gain (or loss) increases. The diminishing sensitivity is observed only on the change in investors' attitude (vector) and not on the investors' attitude itself (scalar). Investors' diminishing sensitivity toward both gains and losses is the reason that the YoY-ROC CAPE indicator is range-bound and why mean reversion occurs more regularly. The original Shiller CAPE is a scalar time series and does not benefit from the third axiom. Therefore the apparent characteristics of range-bound and mean reversion of the scalar Shiller CAPE in the past are the exceptions, not the norms.
Concluding remarks
The stock market is influenced by different driving forces including economic cycles, credit cycles, Fed policies, seasonal/calendar factors, equity premium anomaly, risk aversion shifts the equity premium puzzle and bubble/crash sentiment. At any point in time, the stock market is simply the superposition of the displacements of all these individual waves. Economic cycle is likely the dominant wave that drives cyclical markets, but it is not the only one. That's why the R-squared is only at 29.2% and not all bear markets were accompanied by recessions (such as 1962, 1966 and 1987).
The credibility of the Primary-ID model in gauging primary cyclical markets is grounded on several factors. First, it is based on a fundamentally sound metric – the Shiller CAPE. Second, its indicator (YoY-ROC CAPE) is a vector that is more robust than a scalar. Third, the model tracks the cycle dynamics between the market and the economy relatively well. Forth, the excellent agreement between the five-year average signal length of Primary-ID (0.2 trades per year shown in Figures 5B and 7B) and the average business cycle of 4.7 years reported by NBER adds credence to the model. Finally, the Primary-ID model has firm theoretical underpinnings in behavioral economics.
It's a widely held view that the stock market exhibits both primary and secondary waves. If primary waves are predominantly driven by economic cycles, what drives secondary waves? Can we model secondary market cycles with a vector-based approach similar to that in Primary-ID? Can such a model complement or even augment Primary-ID? Stay tuned for Part 2 where I debut a model called Secondary-ID that will address all these questions.
Theodore Wong graduated from MIT with a BSEE and MSEE degree and earned an MBA degree from Temple University. He served as general manager in several Fortune-500 companies that produced infrared sensors for satellite and military applications. After selling the hi-tech company that he started with a private equity firm, he launched TTSW Advisory, a consulting firm offering clients investment research services. For almost four decades, Ted has developed a true passion for studying the financial markets. He applies engineering design principles and statistical tools to achieve absolute investment returns by actively managing risk in both up and down markets. He can be reached at [email protected].