My friend Mark Hulbert once had a philosophy professor at Oxford, who distinguished two ways of being wrong: “You can be just plain wrong, or you can be wrong in an interesting way.” In the latter case, Mark explained, correcting the wrong reveals a lot about the underlying truth.
The willingness to learn from our own errors, and those of others, is how a great deal of learning comes about. That’s certainly true biologically, where most of our skilled movements rely on feedback and progressive error-correction. It’s also true of invention and research. As Thomas Edison said, “I have not failed. I’ve just found ten thousand ways that won’t work. Many of life’s failures are people who did not realize how close they were to success when they gave up.”
In the past few decades, I’ve tested hundreds of propositions about the financial markets, many advanced by other market analysts, against historical data in order to test their validity. A couple of years ago, for example, several analysts argued that the ratio of U.S. market capitalization to GDP was no longer a valid measure of valuation, because of the substantial increase in foreign revenues of U.S. corporations. Others argued that U.S. GDP should be replaced by global GDP in the denominator. Examining decades of historical data, however, one finds that while foreign revenues of U.S. corporations are greater than in the past, the change has been fairly smooth over the past several decades, and the relative impact is far smaller than investors seem to imagine (one can’t simply reduce current valuations by one-third and leave all prior valuations unchanged). Meanwhile, replacing U.S. GDP by global GDP produces an apples-to-oranges measure that, not surprisingly, weakens its relationship with subsequent market returns.
Still, both proposals were wrong in an interesting way. The foreign revenues of U.S. corporations do matter, and by explicitly estimating them, we developed a valuation measure (MarketCap/GVA) that is even better correlated with actual subsequent S&P 500 total returns, and is more reliable than any other valuation measure we’ve examined in market cycles across history (including MarketCap/GDP, Tobin’s Q, Shiller’s CAPE, price/forward operating earnings, the Fed Model, and numerous others).
As Mark observed, correcting the error "reveals a lot about the underlying truth."
Error-learning
If we’re going to discuss anyone’s errors, it’s best to begin with my own. Even those who are familiar with this narrative are encouraged to review the brief discussion below, not least because this one includes an illuminating chart.
The investment discipline I advocate is decidedly focused on the complete market cycle. Though I’ve typically been frustrated during late-stage bubble advances, I’ve also shifted to a constructive or leveraged investment outlook after every bear market in more than three decades as a professional investor. Despite periodic frustrations, our value-conscious, historically-informed discipline put us ahead in every complete market cycle through 2009.
In late-2008, during a market collapse that we fully anticipated, and with the S&P 500 down more than 40% from its highs, I shifted to a constructive market outlook. As I noted at the time, the prior overvaluation of the market had been erased, and prospects for future long-term returns had substantially improved. Unfortunately, the behavior of the market and the economy (particularly employment losses) became entirely “out-of-sample” from the standpoint of the post-war data on which our market return/risk classification methods were based, and in 2009, I insisted on stress-testing them against Depression-era data. During the Depression, valuation levels similar to those of 2009 were followed by a further loss of two-thirds of the market’s value, and our existing measures of “early improvement in market action” would have been repeatedly whipsawed. Given that potential, I insisted on boosting the robustness of our methods to Depression-era data, post-war data, and also “holdout” validation data. At the time, I discussed this effort as our “two data sets problem,” and in the midst of that ambiguity, we missed a substantial rebound that both our pre-1999 methods and our current methods could have captured.
There were also knock-on effects from quantitative easing. The resulting “ensemble” methods performed better across every data set than our existing methods, and strengthened our confidence in the usefulness of combining valuations and market action when classifying return/risk conditions. But they also captured a historical regularity that turned out to be our Achilles Heel in the face of the Federal Reserve’s zero interest rate policy. In prior market cycles across history, the emergence of extreme “overvalued, overbought, overbullish” syndromes was regularly accompanied or quickly followed by a shift toward risk-aversion among investors (which we infer from the uniformity of market action across a wide range of securities and security types). Because of that overlap, these “overvalued, overbought, overbullish” syndromes, in and of themselves, could historically be taken as reliable warnings of likely air-pockets, panics, or crashes.
Unfortunately, the Federal Reserve’s zero interest rate policies disrupted that overlap. With the relentless encouragement of the Fed, investors came to believe that there was no alternative to speculating in stocks, and even obscene valuations and overextended conditions were followed by further speculation, without any shift toward risk-aversion. In the face of zero interest rates, it was necessary to wait until market internals deteriorated explicitly before adopting a hard-negative market outlook. We implemented that restriction to our approach in 2014.
Clearly, our persistent defensiveness in response to overvalued, overbought, overbullish conditions was wrong in the face of zero interest rate policy. Still, correcting that wrong revealed a lot about the underlying truth.
The lesson to be learned was not that QE or zero interest rates are omnipotent in supporting stock prices. The lesson was not that valuations are irrelevant, or that “this time is different” in ways that investors cannot comprehend. The lesson was not that low interest rates make stocks “cheap” at any price. Rather, the lesson was that in the presence of zero interest rates, yield-seeking speculation can persist even in the face of obscene valuations and recklessly overextended conditions. So while one can become neutral, one has to defer a hard-negative market outlook until the uniformity of market internals explicitly deteriorates (signaling a shift toward increasing risk-aversion among investors).
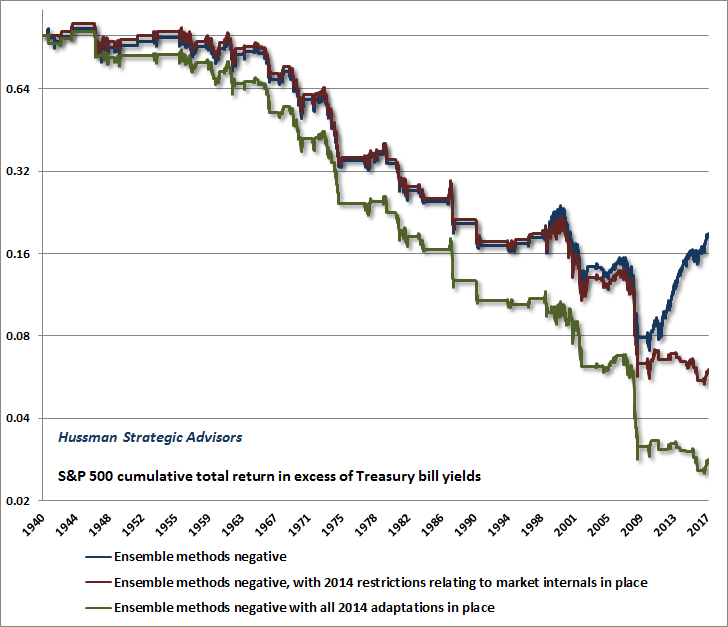
The chart below illustrates the impact of the restrictions we imposed in 2014. The blue line shows the cumulative total return of the S&P 500, over and above Treasury bill yields, in periods where our ensemble methods identified a strictly negative market return/risk profile. Prior to quantitative easing, the market regularly lost value when prevailing market conditions were associated with a negative return/risk profile. The advance in the blue line shows how the Federal Reserve’s deranged monetary experiment changed that dynamic. The red line shows the cumulative total return of the S&P 500, including the restrictions relating to market action that we imposed in 2014. The green line reflects all adaptations we introduced in 2014 to narrow the classification of market conditions that have been particularly hostile to stocks in market cycles across history. This is probably the clearest illustration of exactly the source of our difficulty since 2009, and exactly how we addressed it. Note that the data below is historical, does not depict the returns of any investment portfolio, and does not ensure that future outcomes will be similar to historical market behavior.

You’ll notice a little upward blip upward in the red line during the past year. Despite a market loss in early-2016, the S&P 500 is now higher than when we imposed those adaptations in 2014. Still, it’s clear that the vast majority of our frustration in the advancing half-cycle since 2009 is captured by the difference between those blue and red trajectories. We currently classify market conditions as hard-negative, based primarily on extraordinary market overvaluation on reliable measures, coupled with continued dispersion in our most reliable measures of market action. That view will change with market conditions. From a full-cycle perspective, I expect that the entire market gain since 2014 will be wiped out rather easily, as a prelude to far deeper market losses.
How I abetted the second most offensive market bubble in history
Before we continue, be sure to understand the actual lesson from my own difficulty during the advancing half-cycle since 2009. The lesson is that in the face of quantitative easing and zero interest rates, even persistent overvalued, overbought, overbullish syndromes are not enough to warrant a hard-negative market outlook; one has to wait for extreme valuations to be joined by deterioration in the uniformity of market internals.
My concern is that investors have instead learned an entirely wrong and very dangerous lesson, and have come to believe that valuations are irrelevant, “this time is different,” central banks are omnipotent, and stocks will maintain a permanently high plateau even in the presence of deteriorating market internals.
Yes, it’s certainly possible that future central bank interventions will encourage fresh episodes of speculation, but the inclination of investors to speculate should be read directly from the behavior of market internals. That’s a critical distinction, because Wall Street seems to have forgotten that the Federal Reserve eased persistently and aggressively throughout both the 2000-2002 and 2007-2009 market collapses.
I’ve been doing this for a very long time, and rather admirably in every complete market cycle outside of the recent half-cycle advance. When I left the academic world nearly 20 years ago, I decided that writing was how I would continue to teach. Learning from my mistakes, and from my successes, is absolutely free. I guarantee that there will be a test, and it will most likely come in the form of a rather brutal pop-quiz.
Let me quickly recap some of the most important investment lessons of the past 30 years. My career as a professional investor began with a strong orientation toward value; the idea that every security is a claim to a stream of expected future cash flows that will be delivered into the hands of investors over time, and that prices and expected returns are tightly linked. Never forget that, because it remains reliably true on a 10-12 year horizon, and valuations substantially mold the return/risk profile that investors face over the completion of any market cycle.
Until the late-1990’s tech bubble, that discipline alone, and actions based on it, also served very well even over fairly short periods of time. But as the bubble took hold, the increasingly elevated valuations encouraged many investors to believe that valuations no longer mattered. I was convinced that conclusion was wrong. But it was wrong in an interesting way. Given the market extremes of 1929, 1972 and 1987, it was clear that overvaluation itself was not always enough to drive prices lower. For me, the real question was “what distinguishes an overvalued market that continues to advance from an overvalued market that drops like a rock?”
Based on a century of market evidence, I concluded that the distinction is the psychological preference of investors toward speculation or toward risk aversion. Moreover, I found that the most reliable measure of those preferences was the uniformity or divergence of market action across a broad range of internals, including individual stocks, industry groups, sectors, and asset classes, including debt securities of varying creditworthiness. That distinction proved to be extraordinarily valuable. The combination of extreme valuations and deteriorating market internals is precisely what allowed us to anticipate the 2000-2002 and 2007-2009 market collapses.
It's at that point that I shot myself in the heel. My 2009 insistence on stress-testing our methods against Depression-era data inadvertently resulted in methods that captured an additional historical regularity about “overvalued, overbought, overbullish” conditions, which held in prior market cycles across history, but ultimately failed in the presence of zero interest rates. Correcting that error revealed a lot about the underlying truth: the psychological preferences of investors toward risk matter, regardless of how extreme valuations become, and even regardless of entire syndromes of extreme conditions. Just as in the tech bubble and the mortgage bubble, the status of market internals is essential.
I suspect that I may have actually contributed to the recent valuation bubble. See, as the designated poster-boy for the argument that “this time is different,” the awkward 2009-2014 episode that inadvertently followed my 2009 stress-testing decision makes it easy to dismiss any concern about market risk simply by mentioning my name. Without that miss (and especially having shifted to a constructive outlook in October 2008 after the market was down by over 40%), the similarity of current market risks to those I identified in 2000 and 2007 might be more obvious, and investors might be less inclined to dismiss obscene valuations altogether.
The danger here is considerable. Market internals have already deteriorated on our most reliable measures, and while it’s possible for conditions to change (and our outlook will change accordingly), investors risk severe market losses if they don’t.
The best thing to do when you’re wrong is to correct the error and speak your truth. There may be some benefit to others. So please, reconsider the misguided assumption that stocks will maintain a permanently high plateau, particularly if your financial security relies on that outcome. As for me, informed by the lessons from a century of market history, nearly everything I have is invested in our own discipline, and I’m excited about it.
“Cheap relative to interest rates”
A few more assertions about the financial markets may be useful to discuss. One with appeal to many investors is the idea that valuations may be high on an absolute basis, but that stocks are still “cheap relative to interest rates.” This too is wrong, but wrong in an interesting way.
As I’ve detailed previously (see The Most Broadly Overvalued Moment in Market History), investors often misinterpret the form, reliability, and magnitude of the relationship between valuations and interest rates, and become confused about when interest rate information is needed and when it is not. Specifically, given a set of expected future cash flows and the current price of the security, one does not need any information about interest rates at all to estimate the long-term return on that security. The price of the security and the cash flows are sufficient statistics to calculate that expected return. For example, if a security that promises to deliver a $100 cash flow in 10 years is priced at $82 today, we immediately know that the expected 10-year return is (100/82)^(1/10)-1 = 2%. Having estimated that 2% return, we can now compare it with competing returns on bonds, to judge whether we think it’s adequate, but no knowledge of interest rates is required to “adjust” the arithmetic.
One intuitive way to evaluate the impact of interest rates is to consider the effect of a given departure of interest rates from normal levels. For example, consider again a $100 cash flow that will be received 10 years from today. If the typical return on such an investment is 6%, the current price will be $55.84. But suppose we expect returns to be held down to just 4% for the first 5 years, then 6% after that. In that case, the current price will be $100/[(1.04)^5 x (1.06^5)] = $61.42. That’s 10% higher than our previous calculation. Why? Because in order to reduce the return from 6% to 4% for the initial 5 year period, the price has to increase by 2% x 5 years = 10%.
Accordingly, if you believe that market valuations should be tightly related to the level of interest rates (the correlation actually goes the wrong way outside of the 1970-1998 period, but let’s assume otherwise), it follows that if interest rates are expected to be 3% below average for the entire decade ahead, market valuations ought to be 30% higher than historical norms. The problem is that the most reliable valuation measures (those most tightly correlated with actual subsequent market returns in cycles across history) are currently between 130-160% above their respective historical norms.
An invitation to waterfall market losses
A more systematic way to think about the question of “stocks relative to bonds” is to imagine we want to fund a stream of future spending by looking individually at the next 35 years. For each year, we fund that particular year’s spending by choosing to invest in the S&P 500, 30-year bonds, 10-year bonds, or Treasury bills, depending on the estimated expected return of each over that horizon, less a modest penalty for risk. For example, based on the current level of MarketCap/GVA, we presently estimate 12-year average annual nominal total returns of just 0.6% annually for the S&P 500 Index, and because Treasury yields are low enough to be quite close to the average yield we estimate for Treasury bills over the coming 12-years, the 12-year cash flow would be assigned to T-bills. We do this same exercise for every cash flow from 1 year to 35 years into the future.
When we estimate the investment allocations for a 35-year spending plan in historical data, we find that an investment allocation of more than 60% in the S&P 500 would have been reasonable in more than 70% of all periods since 1940, and an allocation of more than 90% to the S&P 500 would have been reasonable at points when stocks were undervalued relative to historical norms (although temporary drawdowns are sometimes substantial unless measures of market action are included). But while the mathematics of returns are favorable toward stocks at normal levels of valuation, they become quite hostile to stocks at high valuations, because overvaluation can infect expected total returns over a very long horizon.
For example, given the current level of 2.03 for MarketCap/GVA compared with a historical median of less than 1.0, the current dividend yield of 2% on the S&P 500, and expected long-term nominal revenue growth prospects of about 4% (which would be double the revenue growth of the S&P 500 over the past decade, and higher than the 3% growth since 2000), a reasonable estimate for 20-year S&P 500 total returns would be:
(1.04)*(1.0/2.03)^(1/20)+.02-1 = 2.4% annually.
So even on a 20-year horizon, a risk-adjusted allocation would lean toward bonds or Treasury bills here.
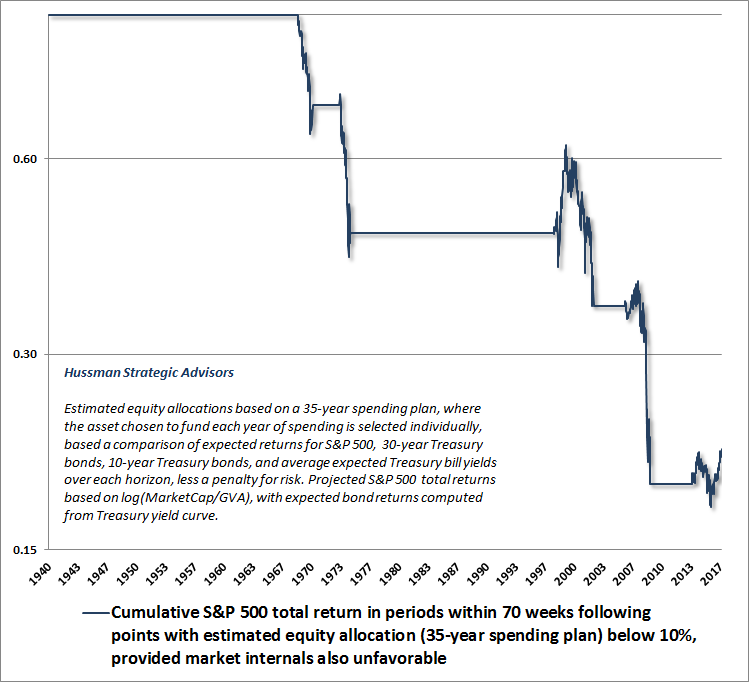
Historically, fewer than 12% of all periods would reduce the appropriate estimated allocation to equities below 10% (based on a 35-year spending plan). These periods include 1969, 1973, 1998-2000, 2006-2007, and 2014-2017. Since we know that overvaluation often has little impact when market internals are still favorable, we use our measures of market internals below as an additional filter. The following chart shows the cumulative total return of the S&P 500 in the 70 weeks following points where the estimated appropriate allocation to stocks was less than 10%, provided that market internals were also unfavorable on our measures. A 70 week horizon was chosen because a typical bear market extends for about a year and four months, on average. Even in these conditions, the S&P 500 did enjoy some temporary gains approaching the 2000 and 2007 market peaks (most frustratingly during 1999 as tech stocks advanced even as the broader market languished), and has done so again in the current instance. Still, two things should be clear: 1) stocks are not presently “cheap relative to interest rates” and, 2) the combination of overvaluation and divergent market internals is ultimately an invitation to waterfall market losses.
“Profit margins will remain permanently elevated”
In recent weeks, I’ve addressed the issue of why profit margins have been elevated in recent years, which has everything to do with labor market slack and weak growth in real unit labor costs, neither which we view as a permanent feature of the U.S. economy (see This Time is Not Different, Because This Time is Always Different, and Paying Twice).
An additional theory crossed my desk in recent weeks, which is that corporate profits are enjoying a “winner take all” phenomenon, which will allow large, dominant companies to retain monopoly-like profit margins indefinitely. Now, there’s no question that many internet-related companies have benefited from network effects that have substantially contributed to their size, as well as their market capitalizations. The question is whether this effect now dominates the profit margin behavior of U.S. corporations more generally. One anonymous analyst, who we like quite a bit for his (or her) analytical approach even when we wholly disagree, recently proposed that profit margins might be more broadly affected by this sort of systematic “winner take all” dynamic.
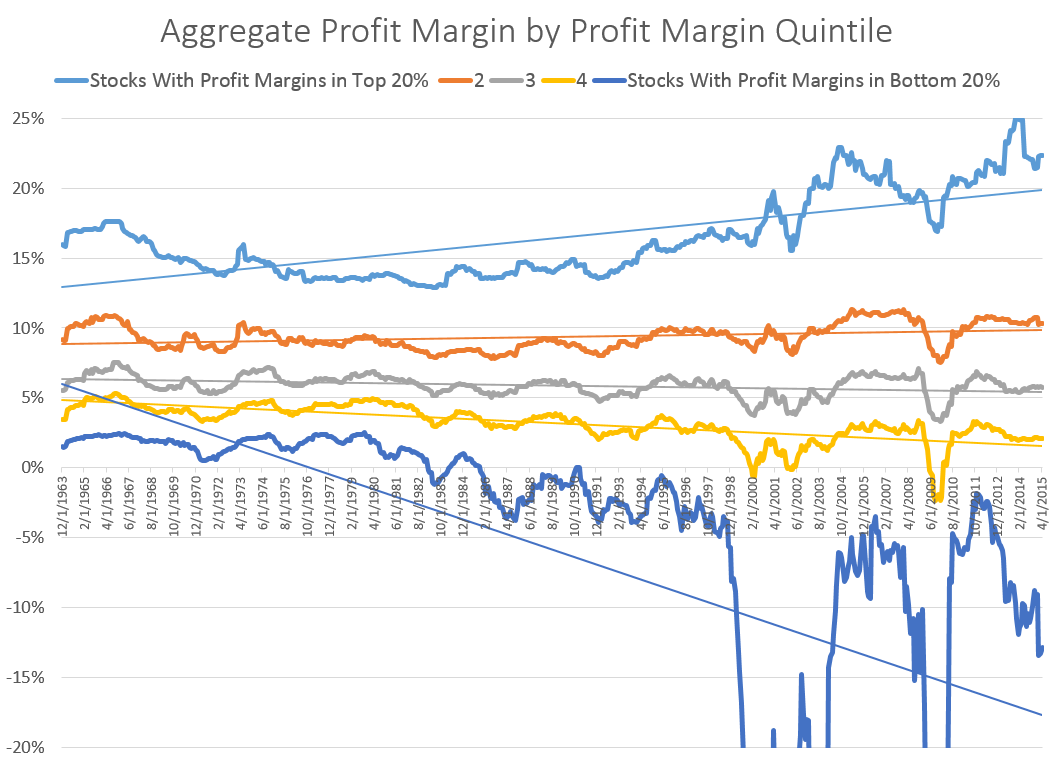
To that end, Patrick O’Shaughnessy compiled some data by separating companies into five bins based on their profit margins, and then charted the aggregate profit margins of each bin (chart below). The analyst proposed, “If our explanation is correct, then the aggregate profit margins of the higher bins should have increased more over the last few decades than the aggregated profit margins of the lower bins. Lo and behold, that’s exactly what the data shows.”
My response to this is straightforward. The conclusion is wrong, but it’s wrong in an interesting way. That’s not a criticism of either analyst, just an issue with the conclusion being drawn, and it provides an opportunity to learn something valuable. The problem here is that the analysis is an artifact of selection bias.
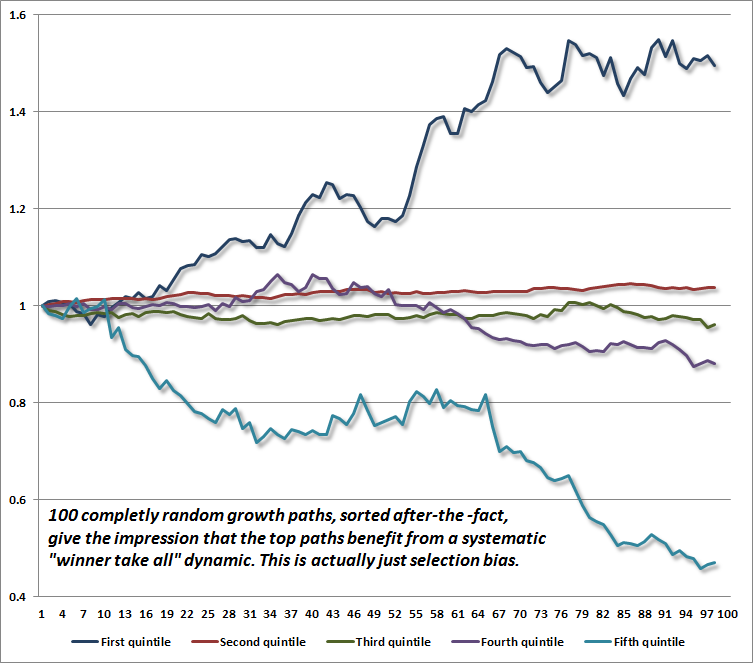
To illustrate, I generated 100 geometric random walks, and then sorted them into quintiles based on their ending values. It should be clear that the members of the top bin are, by definition, the ones that have benefited the most from randomness, and the members of the bottom bin are, by definition, the ones that have suffered the most from randomness. Even though the underlying paths are random going forward, grouping them by their ending values and then looking backward gives the impression that there is some systematic “winner-take-all” process at play.
That’s not to say that we can reject the possibility of a “winner-take-all” dynamic, but what’s actually required to demonstrate it is to sort the series at some point T, and then show that subsequent outcomes are systematically biased in favor of the early winners. Again, there’s no question that many internet companies benefit from this kind of dynamic (though their market capitalizations already vastly extrapolate the continued expansion of those network effects). For the market as a whole, however, I remain convinced that the main story behind profit margin expansion in recent years has been weak growth in real unit labor costs, and that this is likely to change in the years ahead, as the combined result of weak demographic growth in the labor force, substantially less slack in the U.S. labor market, and limited benefits from labor outsourcing on unit labor costs, given that lower wages often go hand-in-hand with lower productivity.
© Hussman Funds
© Hussman Funds
Read more commentaries by Hussman Funds